让sprocess代码分段运行
sprocess调试的时候一大问题:仿真进行到后半部分,有个地方写错了,修改之后就要连前面部分一起重新跑一遍。非常耗时
解决办法有俩
1.手动给代码分段,放到多个sprocess tool里面。在前一个sprocess输出结构,后一个再载入前面输出的文件,接着跑
2.用#split命令,划分代码这样它就会自动分段,修改后面的代码内容,前面的部分可以无需重新跑一遍
直接说方法2
#split命令的介绍在help→manual→Sentaurus Workbench里面,搜#split就能搜到了

#用法
command 1
command 2
#split @epi1@
command 3
command 4
#split @imp@
command 5
command 6
然后在SWB的project里添加@ABC1@和@ABC2@参数,比如下面这样
参数填0或者随便什么东西都可以,参数名也可以随便取
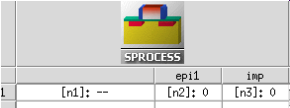
这样它在运行完command 1,2的时候就会自动保存一个结构
然后到下一个node(图中的就是@epi1@节点),自动载入刚刚保存的结构,运行command 3,4,运行完再自动保存
再到下一个节点,继续上面的操作
要看它epi1的形貌,右键n2节点,QuickVisualize就能看了
如果要修改imp后的内容,从n3开始重新跑就可以了
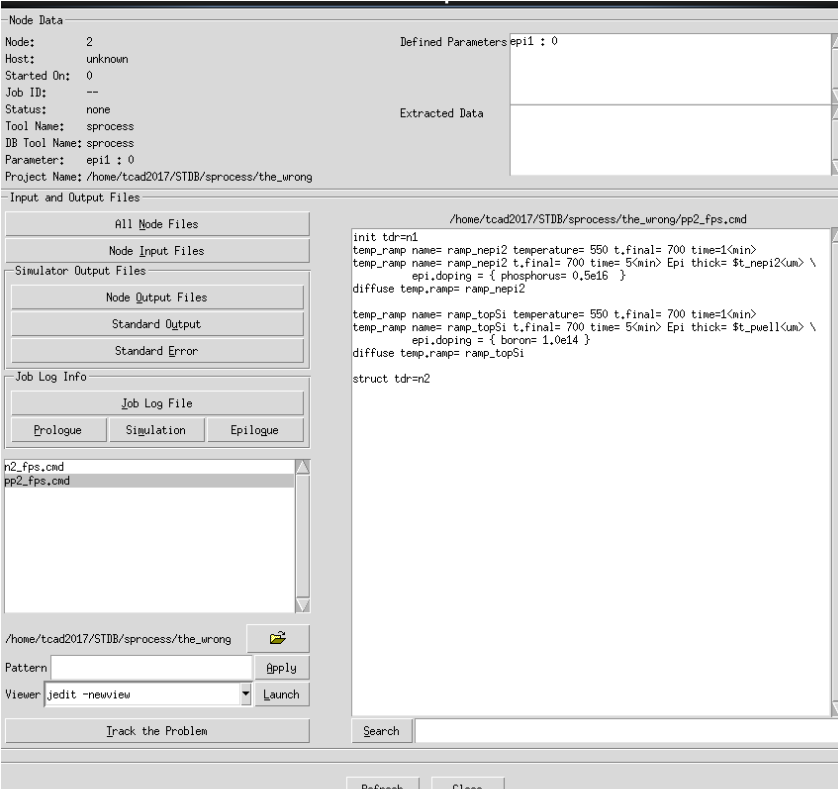
要看某个节点的实际代码内容,对节点preprocess之后,双击,在左下选pp*_fps.cmd就能看到
#header和#endheader
有一些代码,某几段运行会用到,那就需要放在这俩之间,如
#header
pdbSet balabala
#define _Imp_tilt_ 7
mask name= imp_mask segments={0 1 4 5}
#endheader
这样后面的每一个节点代码,开头都是
pdbSet balabala
#define _Imp_tilt_ 7
mask name= imp_mask segments={0 1 4 5}
command 123
command 456
P.S. 所以说注释的开头,一定要多打几个####,不然说不定就和某个关键字装上了